
Как это работает?
Big Data работает на принципе: чем больше вы знаете о чем-либо, тем точнее вы можете предсказать, что случится в будущем. Сравнение отдельных данных и отношений между ними (речь идет об огромном количестве данных и невероятно большом количестве возможных связей между ними) позволяет обнаружить ранее скрытые закономерности. Это дает возможность заглянуть внутрь проблемы и в конечном итоге понимание того, как мы можем управлять тем или иным процессом.
Чаще всего процесс обработки больших объемов информации включает в себя построение моделей, базирующихся на собранных данных, и запуск симуляций, в процессе которого постоянно меняются ключевые настройки, при этом каждый раз система мониторит, как «смена настроек» влияет на возможный результат.

Этот процесс полностью автоматизирован, ведь речь идет об анализе миллионов симуляций, перебора всех возможных вариантов вплоть до того момента, пока паттерн (нужная схема) не будет найден или пока не случится «просветление», что поможет решить задачу, ради которой все и затевалось.
Чтобы придать всему этому бесконечному и разношерстному потоку данных практический смысл, Big Data часто использует самые передовые технологии анализа, которые включают в себя искусственный интеллект и машинное обучение (это когда программа в компьютере обучает другие программы).
Компьютеры сами обучаются определять, что представляет та или иная информация — например, распознавать изображения, язык, — и они могут делать это намного быстрее, чем люди.
BIG DATA. Вся технология в одной книге – Андреас Вайгенд читать онлайн бесплатно полную версию книги
Andreas Weigend
Data for the People
Andreas Weigend, 2017
This edition published by arrangement with Levine Greenberg Rostan Literary Agency and Synopsis Literary Agency
Серия «Top Business Awards»
Богданов С., перевод на русский язык, 2018
Оформление. ООО «Издательство «Эксмо», 2018
* * *
Посвящается п., ф. и с.
Пролог
Когда зафиксировано все
Информация как таковая становится самой значительной отраслью экономики, и базы данных знают о каждом конкретном человеке больше, чем известно ему самому. Чем больше информации о каждом из нас попадает в базы данных, тем в меньшей степени мы существуем.
Маршалл Маклюэн
В 1949 году мой отец, в ту пору двадцатитрехлетний молодой человек, получил место учителя в Восточной Германии. Приехав в город, где ему предстояло работать, папа решил, что ему очень повезло: прямо на вокзале он встретил человека, который тоже искал себе жилье и соседа по комнате. Они нашли себе квартиру, но буквально через пару дней сосед исчез. Папа был озадачен. Спустя несколько дней он был уже не на шутку обеспокоен.
Как-то утром, когда он готовил себе завтрак, в дверь постучали. Папа обрадовался – он решил, что сосед вернулся! Но, открыв дверь, увидел каких-то незнакомых людей. Они сообщили, что ему присуждена премия за успехи в деле народного образования. Премию будут вручать в торжественной обстановке, а их прислали, чтобы сопроводить его на церемонию. Папа не слишком поверил сказанному – уж больно угрюмо выглядели эти мужчины в одинаковых плащах. Но выбора у него не было. Когда его затолкали в ожидавшую на улице машину, он с ужасом обнаружил, что ее дверцы не открываются изнутри. Его арестовали советские власти.
Отца обвинили в шпионаже в пользу американцев. Основанием для обвинения послужило его знание английского языка. Ни семья, ни знакомые не знали, где он. Для них он исчез с лица земли. Его бросили в камеру-одиночку тюрьмы, где он протомился следующие шесть лет. Он так никогда и не узнал ни причины своего ареста, ни причины своего освобождения.
Доступ к личной информации человека – реальная угроза его безопасности, поскольку эти данные могут быть использованы ему во вред. В моих глазах этот риск выглядит особенно очевидным и пугающим, в частности, потому, что я знаю, как собирали и использовали личную информацию против моего отца.
Лет через десять после распада ГДР я попросил дать мне возможность ознакомиться с информацией, которую Министерство госбезопасности, Штази, собирало о моем отце до и после его тюремного заключения. Я был далеко не единственным – с момента падения Берлинской стены с просьбами предоставить доступ к досье Штази на себя или на своих близких обратились почти три миллиона человек. К сожалению, в письме от комиссии по архивам Штази сообщалось, что все материалы, касающиеся моего отца, утрачены.
Но в конверте с письмом обнаружилось кое-что еще – фотокопия обложки досье Штази на меня самого. Я был поражен. Штази вела досье на меня? Я же был просто студентом-физиком. Тем не менее агенты госбезопасности начали собирать информацию обо мне еще в 1979 году, когда я был подростком, а датой последнего обновления значился 1987 год, когда я уже переехал в Штаты. От досье осталась только обложка, и я вряд ли когда-нибудь узнаю, что именно собрала на меня Штази, зачем это было нужно и как использовалось, если использовалось вообще.
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950Перейти
Похожие книги
Дуче! Взлет и падение Бенито Муссолини Ричард Колье
RFID-технологии на службе вашего бизнеса Бхуптани Маниш
Жизнь Сезанна Перрюшо Анри
Жизнь Сезанна Перрюшо Анри
Рождение трагедии или Эллинство и пессимизм Ницше Фридрих Вильгельм
Руководство богатого папы по инвестированию Кийосаки Роберт Тору, Лектер Л. Шэрон
Обучение на Big Data Analyst
Аналитику больших данных нужна подготовка в вузах, без высшего образования устроиться на работу практически невозможно
Стоит обратить внимание на следующие направления подготовки:
- «Математика и компьютерные науки» (код: 02.03.01);
- «Прикладная информатика» (код: 09.03.03);
- «Информатика и вычислительная техника» (код: 09.03.01);
- «Программная инженерия» (код: 09.03.04);
- «Механика и математическое моделирование» (код 01.03.03);
- другие направления подготовки, связанные с ИТ, математикой и компьютерными науками, информатикой, вычислительной техникой, управлением в технических системах.
Пока ни один, даже самый крупный российский университет, не выдает дипломы, в которых записано, что выпускник может работать аналитиком больших данных. Но любая из программ, связанных с подготовкой программистов или ИТ-специалистов, станет хорошей базой для того, чтобы после окончания вуза (или параллельно с учебой) пройти курсы и получить профессию именно Big Data Analyst.
И обязательно надо уделить внимание изучению технического английского языка
Курсы
Python, BI и BigData
ProductStar
6 месяцев
Рассрочка
от 3 121 ₽/мес
Цена
74 904 ₽
Смотреть курс
отсрочка платежа
помесячная оплата
чат
от 3 121 ₽/мес
74 904 ₽
Смотреть курс
Вузы
Институт математики, информационных систем и цифровой экономики РЭУ им. Г.В. Плеханова
Прикладная информатика
4 года
260 000 ₽/год
25
бюджетных местИнститут информационных систем и инженерно-компьютерных технологий РосНОУ
Прикладная информатика в экономике
4 года
58 000 ₽/год
10
бюджетных местЦентр развития программ дополнительного и онлайн-образования ДВФУ
Прикладная информатика
5 лет
80 000 ₽/год
нет
бюджетных местВяземский филиал Московского государственного машиностроительного университета
Прикладная информатика
5 лет
28 000 ₽/год
нет
бюджетных мест
Big data в маркетинге
Благодаря Big data маркетологи получили отличный инструмент, который не только помогает в работе, но и прогнозирует результаты. Например, с помощью анализа данных можно вывести рекламу только заинтересованной в продукте аудитории, основываясь на модели RTB-аукциона.
Big data позволяет маркетологам узнать своих потребителей и привлекать новую целевую аудиторию, оценить удовлетворённость клиентов, применять новые способы увеличения лояльности клиентов и реализовывать проекты, которые будут пользоваться спросом.
Сервис Google.Trends вам в помощь, если нужен прогноз сезонной активности спроса. Всё, что надо — сопоставить сведения с данными сайта и составить план распределения рекламного бюджета.
Коротко о главном
- Большие данные — это наборы данных, которые быстро генерируются и поступают из разных источников. Потом эту информацию можно использовать, чтобы составлять прогнозы, статистику, принимать бизнес-решения.
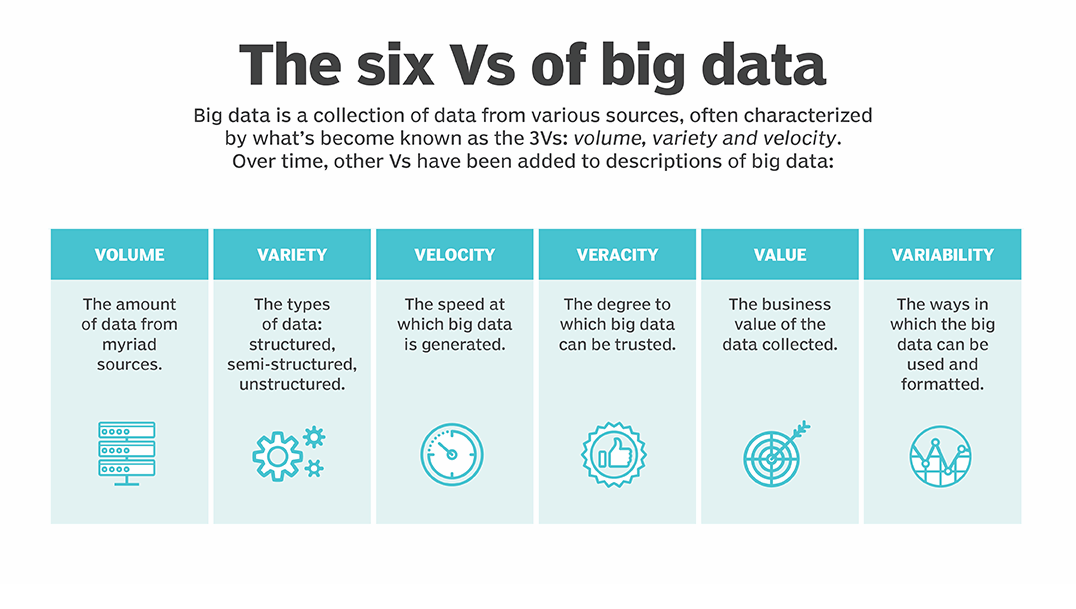
- Есть шесть основных характеристик больших данных: скорость накопления данных, объем, разнообразие, достоверность, изменчивость и ценность.
- Данные в основном поступают из трех источников: социальных (соцсети, приложения, онлайн-сервисы), машинных (оборудование, элементы «умного» дома), транзакционных (финансовые транзакции).
- Данные хранятся в data-центрах с мощными серверами. Обрабатывают данные в распределенных системах хранения данных.
- Для анализа big data используют описательную, диагностическую, прогнозную и предписательную аналитику.
- Большие данные используют в бизнесе, банковской сфере, ретейле, маркетинге, госструктурах, логистике, автомобилестроении, медицине.
- У big data большие перспективы, но есть и сложности: для хранения данных нужна инфраструктура, которая может дорого стоить. Еще, чтобы работать с большими данными, нужно хорошо разбираться в предметной области, а не только в технической части.
*Площадки Meta признаны экстремистскими и запрещены в РФ.
VVV — признаки больших данных

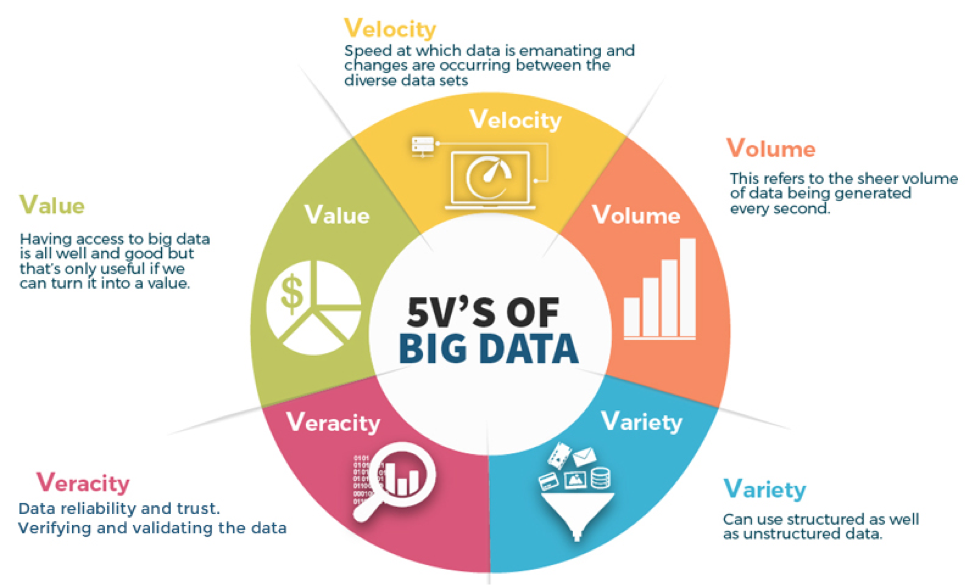
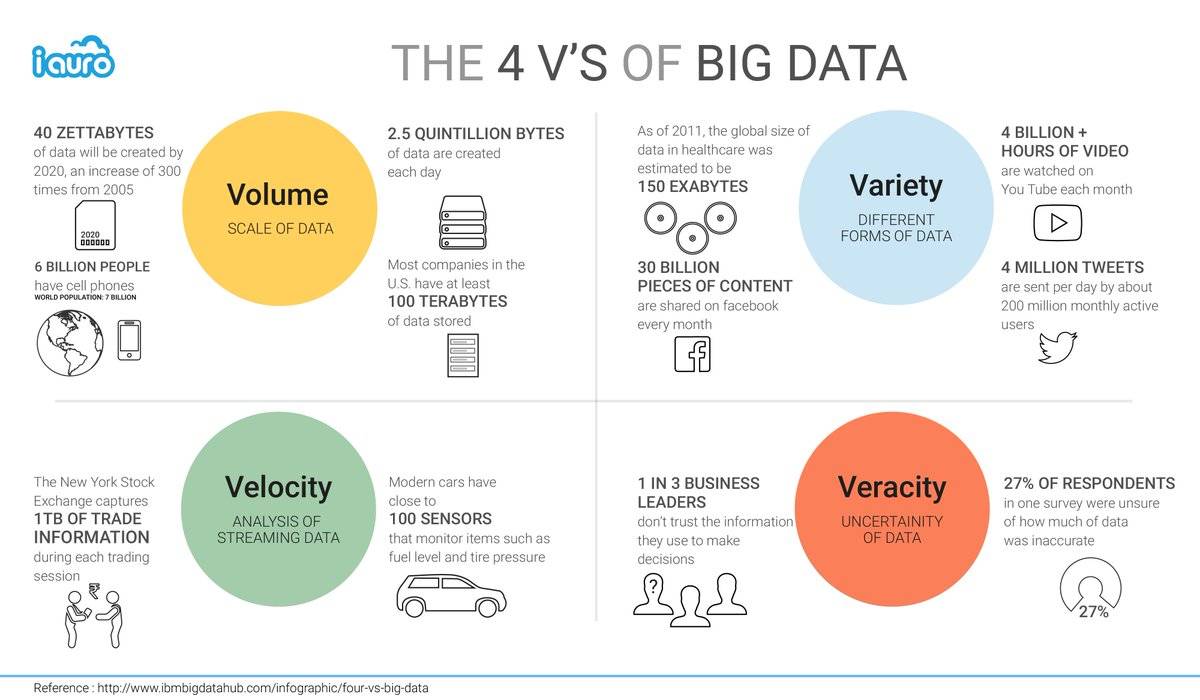
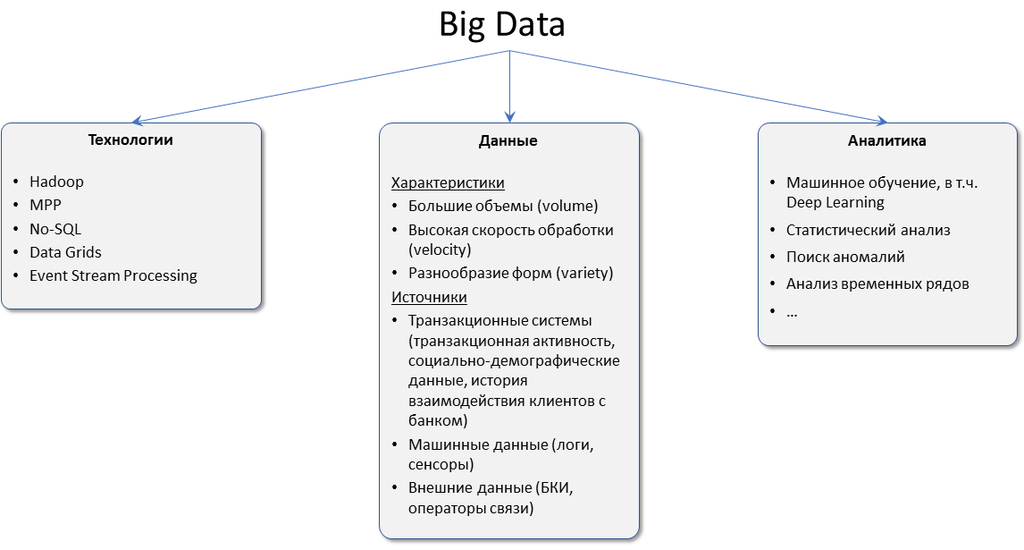
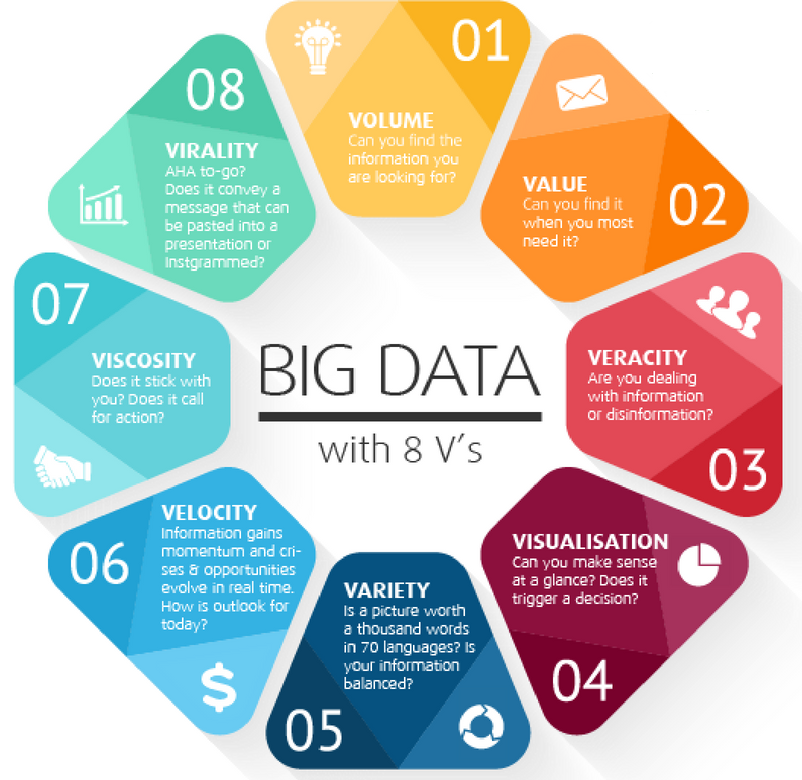
Чтобы уменьшить размытость определений в сфере Big Data, разработаны признаки, которым они должны соответствовать. Все начинаются с буквы V, поэтому система носит название VVV:
• Volume – объём. Объём информации измерим.




• Velocity – скорость. Объём информации не статичен – он постоянно увеличивается, и инструменты обработки должны это учитывать.
• Variety – многообразие. Информация не обязана иметь один формат. Она может быть неструктурированной, частично или полностью структурированной.
К этим трём принципам, с развитием отрасли, добавляются дополнительные V. Например, veracity – достоверность, value – ценность или viability – жизнеспособность.
Но для понимания достаточно первых трёх: большие данные измеримые, прирастающие и неоднообразные.
Чем полезны Big Data быть полезна конечному пользователю
В первую очередь, речь идет о персональных, когда пользователь — субъект и инициатор использования Big Data. Часто на этот вопрос отвечают банальными фразами типа «каждый раз, когда вы пользуетесь поисковыми системами Google или Яндекс, вы работаете с большими данными».
Однако суровая правда заключается в том, что пока разговор о Big Data приложениях для массового пользователям (B2C big data, если хотите) больше похож на рекламные плакаты эпохи «атомного романтизма» 50-х, где домохозяйкам обещают атомные пылесосы, а детям — атомные игрушки. Трудно представить ситуацию, в которой массовый пользователь будет являться не просто источником информации или потребителем готовых приложений, а полноценным участником процесса.
Методы анализа big data
Для анализа можно использовать любые объемы больших данных. Иногда данные сначала структурируют и выбирают нужные для анализа. Вот основные методы анализа big data:
Описательная аналитика. Это анализ, цель которого — дать ответ на вопрос «что случилось?». Пример описательной аналитики — финансовый отчет, который описывает произошедшее, не объясняя причин. Еще пример — статистика активных пользователей соцсети за день.
Диагностическая аналитика. На этом шаге анализа нужно понять: «почему это случилось?». Иногда диагностическую аналитику называют факторным анализом. То есть при анализе выявляют факторы, из-за которых произошли изменения в показателях. Так, финансовые аналитики ежегодно докладывают об изменениях в инфляции и рассказывают, почему она изменилась. Определение факторов, за счет которых изменилась инфляция, — это результат диагностической аналитики.
Прогнозная аналитика. Цель метода — ответить на вопрос «что случится в будущем?». Для анализа используют методы data science, основанные на различных математических концепциях. Прогнозная аналитика — это, как правило, просчитывание вероятности какого-то события в будущем. Например, утверждение «С вероятностью 80% рынок акций на следующей неделе будет расти» — это результат прогнозной аналитики.
Предписательная аналитика. Этот метод считается самым прогрессивным. В нём автоматическая система дает рекомендации к действиям на основе предыдущих анализов. Метод отвечает на вопрос «как поступить?».
Что такое большие данные

Большие данные – современное технологическое направление, связанное с обработкой крупных массивов данных, которые постоянно растут. Big Data – это сама информация, методы её обработки и аналитики. Перспективы, которые может принести Big Data интересны бизнесу, маркетингу, науке и государству.
В первую очередь большие данные – это всё-таки информация. Настолько большая, что ей сложно оперировать с помощью обычных программных средств. Она бывает структурированной (обработанной), и неструктурированной (разрозненной). Вот некоторые её примеры:
• Данные с сейсмологических станций по всей Земле.
• База пользовательских аккаунтов Facebook.
• Геолокационная информация всех фотографий, выложенных за сегодня в Instagram.
• Базы данных операторов мобильной связи.
Для Big Data разрабатываются свои алгоритмы, программные инструменты и даже машины. Чтобы придумать средство обработки, постоянно растущей информации, необходимо создавать новые, инновационные решения. Именно поэтому большие данные стали отдельным направлением в технологической сфере.
Подборка курсов от других школ
Специализация Data Engineer | Otus
Курс для разработчиков, админов СУБД, и других смежных специалистов, которые хотят изучить актуальные инструменты для работы с большими данными.
После обучения вы сможете самостоятельно разворачивать, налаживать, оптимизировать инструменты обработки данных, адаптировать датасеты для дальнейшей работы, создавать специализированные сервисы для применения результатов обработки данных, формировать архитектуру данных внутри компании.
Преимущества:
- Прямое общение с преподавателями.
- Акцент на практических знаниях.
Аналитик Big Data и старт в Data Science | ProductStar
Годовой курс, позволяющий освоить ключевые технологии, научиться эффективно работать с большими данными, повысить свои познания в аналитике, а перейти в профессии на новый уровень. Изучите основной инструментарий: SQL, Python, Hadoop, ETL, DWH.
Преимущества:
- Практические знания.
- Помощь в поиске работы.
- Поддержка персонального ментора.
BIG DATA для менеджеров | ProductLive
Полугодовая программа обучения, рассчитанная на руководителей бизнеса или отдельных департаментов, менеджеров.
В рамках обучения вы узнаете, как грамотно внедрять AI в деятельность компании, использовать возможности больших данных для оптимизации деятельности, повышения эффективности бизнеса.
Преимущества:
- Обучение на реальных кейсах.
- Поддержка личного ментора.
- Защита дипломного проекта.
Курс Data Science academy. Основы | SF Education
В рамках этого курса студенты научатся проводить математические расчеты, эффективно работать с большими данными, программировать на Пайтон, использовать методы машинного обучения.
Программа прекрасно подойдет для бизнес-аналитиков, финансистов, руководителей, которые хотят актуализировать свои знания, начать работать более продуктивно.
Преимущества:
- Разноформатное обучение: разбор кейсов, вебинары, тестирование, лекции.
- Наставники помогут разобраться со сложными темами, уточнить спорные моменты в обучении.
- Удостоверение о повышении квалификации.
Как стать специалистом по Data Science | Школа анализа данных Яндекс
Выпускники этой образовательной программы смогут структурировать и анализировать большие массивы данных, применять машинное обучение для поиска неочевидных закономерностей, прогнозирования событий.
Они смогут оптимизировать работу своих проектов в бизнесе, науке, промышленности. Основные инструменты: Python со специализированными библиотеками Scikit-Learn, XGBoost, а также Jupyter Notebook, SQL.
Преимущества:
- Обучение у топовых специалистов Яндекса.
- Вводный модуль бесплатно.
Data-science и нейронные сети | Университет искусственного интеллекта
Программа рассчитана на 7 месяцев обучения, за это время обещает подготовить специалиста уровня middle. Студенты будут выполнять практические задания, работать над собственным нейросетевым проектом, смогут пройти стажировку.
Преимущества:
- Стажировка.
- Поддержка наставника.
- Акцент на практике.
Специалист по большим данным 15.0 | New Pro Lab
За 3 месяца обучения студенты смогут внимательно изучить основные возможности, технологии в сфере работы с большими данными.
Преимущества:
- Поддержка кураторов.
- Можно пройти программу полностью или по частям.
Data Science | Skill Branch
Ресурс предлагает интересную обучающую программу с экспертом Сбербанка.
За 5 месяцев обучения вы освоите весь необходимый для специалиста инструментарий, разберете реальные кейсы из разных сфер бизнеса, а также выполните множество практических интерактивных заданий для проверки, закрепления знаний.
Преимущества:
- Акцент на практических знаниях.
- Содействие в трудоустройстве.
- Есть бесплатные пробные уроки.
Курс по анализу Big Data | BigData Team
Курс для аналитиков, разработчиков, начинающих специалистов в нашей специализации, который включает 30 часов лекционных материалов, множество практических заданий.
В процессе обучения изучите такие инструменты, технологии: HDFS, Map Reduce, Hive, Spark, RT, NoSQL, Data layout.
Преимущества:
- Поддержка экспертов, наставников.
- Удостоверение о повышении квалификации.
- Обратная связь по домашним заданиям.
Что скрывается за термином Big Data? Какие средства применяются для хранения и работы с большими данными?
Роман Баранов, руководитель направления аналитики компании КРОК
«Если смотреть с точки зрения информационных технологий, то под термином Big Data подразумевается большое количество продуктов. По сути, они не несут в себе что-то принципиально новое, особенно, в части инструментов и возможностей. Думаю, на эту концепцию стоит взглянуть как на маркетинговый термин, который сегодня очень моден.





Если речь заходит про безопасность, то важно не только понимать, какой результат приносит Big Data, но и какими терминами оперирует, а также как получаются те или иные выводы на основе информации. Здесь необходим инструментарий, который будет давать полное представление обо всех потоках данных
Зная, ЧТО хранится, можно понять, КАК защищать системы и информацию».

Алексей Редькин, инженер подразделения стратегического маркетинга «Мицубиси Электрик»
Алексей Редькин, инженер подразделения стратегического маркетинга :
«Большими данными (Big Data) называются массивы информации, которые превышают вычислительные возможности обычных компьютеров, а также технологии для их обработки, анализа и представления в удобном человеку формате. Работа с большими данными стала возможной благодаря новым технологическим достижениям двухтысячных годов. В этот момент IT-специалисты научились распределять большие объемы информации по вычислительным системам и базам данных. Это открыло целый ряд новых областей применения такой информации. Так, работа с Big Data необходима для создания карт, оцифровывания больших массивов информации в фондах и библиотеках, прогнозирования погоды, работы систем общественного транспорта и обработки информации о транзакциях клиентов в банках.
Большие данные применяются и в сфере автоматизированного производства. В этом случае информация, полученная от оборудования, анализируется в реальном времени, и оператору или управленцу транслируется оптимальное решение для производственного или финансового процесса. С помощью Big Data машины также способны сами принимать решения и даже учиться без участия человека. Большие данные тесно связаны с технологиями IoT (интернета вещей) и IoE (интернета всего): физическое пространство и киберпространство с их помощью объединяются. К примеру, показатели производственной линии можно видеть в реальном времени на экране смартфона».
Алексей Краснопольский, директор по продукту «Первого ОФД»
«Столь популярное на сегодняшний день понятие Big Data по сути своей представляет огромный массив информации, для работы с которым требуются специальные средства анализа, методы и алгоритмы, поскольку работа с большими данными посредством существовавших ранее стандартных инструментов является неэффективной. Основная задача Big Data – возможность обрабатывать колоссальные объемы данных и выстраивать на их основе прогнозные модели.
Горизонтальная масштабируемость и высокий уровень отказоустойчивости – вот основные принципы, на которых выстраивается работа с Big Data».
Аналитика Big Data реалии и перспективы в Росси и мире.
О больших данных сегодня не слышал только человек, который не имеет никаких внешних связей с внешним миром. На Хабре тема аналитики Big Data и смежные тематики популярны. Но неспециалистам, которые хотели бы посвятить себя изучению Big Data, не всегда ясно, какие перспективы имеет эта сфера, где может применяться аналитика Big Data и на что может рассчитывать хороший аналитик. Давайте попробуем разобраться.
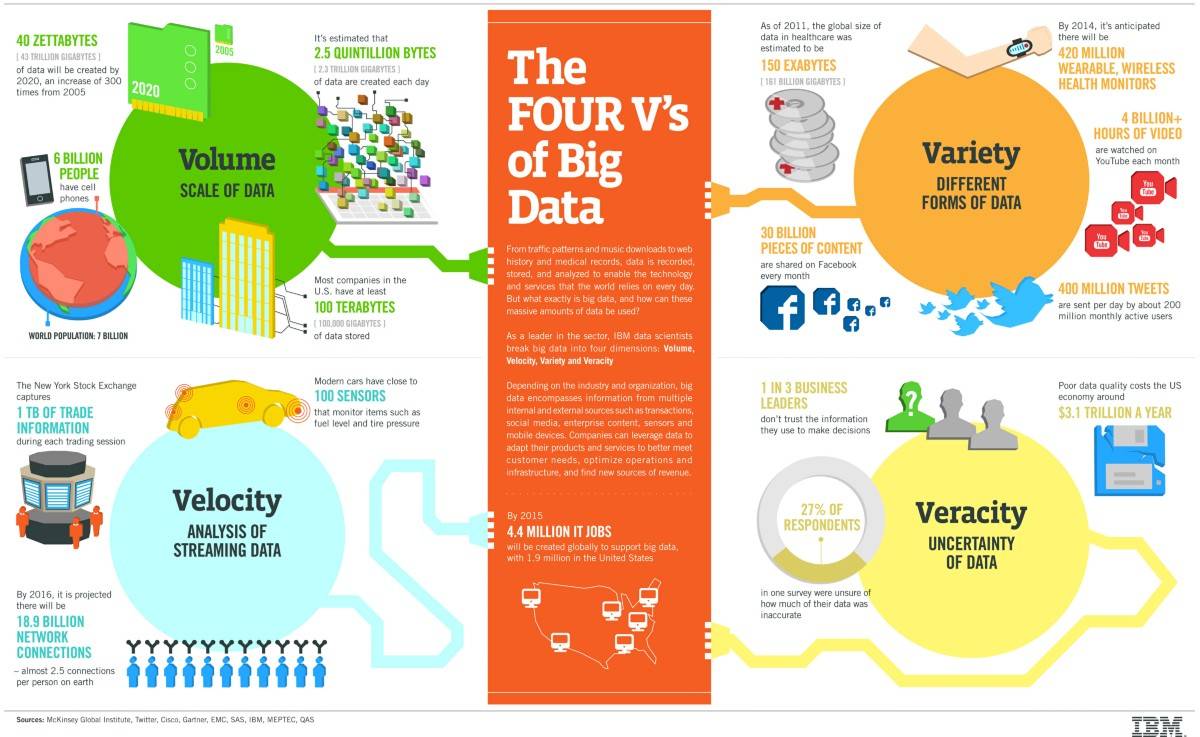
С каждым годом увеличивается объем генерируемой человеком информации. К 2020 году объем хранимых данных увеличится до 40-44 зеттабайт (1 ЗБ ~ 1 миллиард ГБ). К 2025 году — до примерно 400 зеттабайт
Соответственно, управление структурированными и неструктурированными данными при помощи современных технологий — сфера, которая становится все более важной. Интересуются большими данными как отдельные компании, так и целые государства.
К слову, именно в процессе обсуждения информационного бума и способов обработки генерируемых человеком данных и возник термин Big Data
Считается, что впервые его предложил в 2008 году редактор журнала Nature — Клиффорд Линч.
С тех пор рынок Big Data ежегодно увеличивается на несколько десятков процентов. И эта тенденция, по мнению специалистов, будет держаться и дальше. Так, по оценкам компании Frost & Sullivan в 2021 году общий объем мирового рынка аналитики больших данных увеличится до показателя в $67,2 млрд. Ежегодный рост составит около 35,9 %.
Технологии и методы анализа, которые используются для анализа Big Data:
- Data Mining;
- краудсорсинг;
- смешение и интеграция данных;
- машинное обучение;
- искусственные нейронные сети;
- распознавание образов;
- прогнозная аналитика;
- имитационное моделирование;
- пространственный анализ;
- статистический анализ;
- визуализация аналитических данных
Методы сбора и хранения больших данных
Анализ больших данных позволяет оценивать все факторы, способные повлиять на решение. Если говорить точнее, Big Data используется для построения моделей-симуляций, обеспечивающих возможность тестирования идеи, продукта.
 Методы сбора и хранения больших данных
Методы сбора и хранения больших данных
Основными источниками, применяемыми при анализе больших данных, являются:
- интернет вещей (IoT) и устройства с доступом к нему;
- социальные сети, блоги и средства массовой информации;
- данные компаний о транзакциях, заказах товаров, поездках на такси и каршеринге, профили клиентов;
- сведения с приборов, таких как метеостанции, измерители состава воздуха, водоемов, информация, поступающая от спутников;
- статистика субъектов и государств, включающая в себя данные о перемещениях, рождении и смертях граждан;
- данные медицинского характера, в том числе анализы, болезни, снимки, применяемые для диагностики.
В 2007 года ФБР и ЦРУ начали использовать «PRISM», известный как одна из наиболее современных систем сбора персональных данных пользователей соцсетей, сервисов «Microsoft», «Google», «Apple», «Yahoo». Также он записывает общение людей по телефону.
Сегодня вычислительные системы открывают доступ к огромным массивам информации, для хранения которой создают дата-центры с мощнейшими серверами. Используются не только традиционные, материальные серверы, но и облачные хранилища, так называемые «озера данных» или «data lake», то есть содержащие большой объем сведений из одного источника, не имеющий четкой структуры.
Применяют «Hadoop», фреймворк с набором утилит, направленных на разработку и выполнение программ распределенных вычислений. Анализ больших данных производится за счет современных инструментов, в основе которых лежат самые современные методы интеграции и управления, подготовки сведений для нужд аналитики.
Как мы сталкиваемся с Big Data каждый день?
Человек — главный генератор и потребитель больших данных. Ежедневно мы создаем столько новой информации, сколько раньше создавали десятилетиями
Не важно, что большая часть этого — наши селфи. Сейчас 90% имеющейся информации было создано за последние два года
Мы генерируем информацию не только при помощи фоточек и социальных постов. Это каждый наш поисковый запрос, шаг, посчитанный фитнес-трекером, видео, просмотренное на YouTube.
Только в Google совершается около 40 000 поисковых запросов ежесекундно, что дает около 1,2 триллиона поисковых запросов для больших данных ежегодно.
И с каждым днем количество данных увеличивается все быстрее. Если сегодня мы генерируем 4,4 зетабайта данных, то к 2020 мы будем создавать уже 44.
К 2020 году почти треть всех данных будет проходить через облачные сервисы, а значит будет подвергнута анализу.
Интересно, что для анализа больших данных не всегда используются компьютеры корпораций. Часто пользователи сами предоставляют свои компьютеры для решения различных научных задач. В это же время 73% организаций проинвестировали или собираются проинвестировать в развитие больших данных.
Крупные компании типа Google, Facebook и даже государства обрабатывают и используют эту информацию для улучшения нашего образа жизни. Ну, или для показа более релевантной рекламы.
Если упростить, то большие данные собираются из нескольких источников:
- Открытые данные: социальная, экономическая и прочая публичная информация о городах, странах. Данные о законодательствах, статистика спортивных мероприятий. По сути, любая открытая справочная информация.
- Социальные сети: всё то, что мы с вами добровольно рассказываем Facebook и ВКонтакте. Даже если пост не публичный, он становится частью Big Data. В среднем пользователи Facebook пишут около 31,25 миллионов сообщений и просматривают 2,77 миллионов видео каждую минуту.
- Интернет вещей — это ещё один интересный термин. Если ваш холодильник имеет доступ в интернет, значит ваши продукты — тоже большие данные. Любые сенсоры в телефоне, смарт-часах, фитнес-трекерах передают самую различную информацию о вас и ваших занятиях. Например, в 2016 году было продано около 1,4 биллиона (больше миллиарда) смартфонов. В каждом из которых есть множество сенсоров для сбора данных об их владельце. И с каждым годом появляется всё больше вещей с интернет-доступом, а еще вчера они замечательно работали и без него.
- Личные данные тоже становятся частью больших данных. Часто эти данные обезличены: данные вашей медицинской карты, списки дел и так далее.
- Коммерческие транзакции. Речь не только о банковских транзакциях, но и о любых платежах в интернете.
- Любой другой контент, создаваемый нами: видео на YouTube, фотографии в Instagram. Каждую минуту мы загружаем 300 часов видео на YouTube, а в 2015 году загрузили около триллиона фотографий, из которых миллионы доступны публично. К концу 2017 года 80% всех фотографий будет сделано на смартфон
Всё это пугает и иногда хочется спрятаться под камень и добывать огонь при помощи двух палок. Однако, за Большими данными — будущее и приходится мириться с тем, что Великий Компьютер знает про нас всё. Хотим мы этого или нет. На основе этих данных мы можем не только получать таргетированную рекламу, ориентированную только на нас, но и значительно улучшить нашу жизнь. Только большинство не понимает, как происходит это улучшение и пугается любого упоминания о биг дате.
Если вас уже поразили размеры того, сколько информации обрабатывается, то вот ещё один интересный факт. Сегодня обработке подвергается лишь 0,5% всех доступных данных. Поэтому самое интересное всё еще впереди.
Big data в банках
Помимо системы, описанной выше, в стратегии «Сбербанка» на 2014-2018 гг
говорится о важности анализа супермассивов данных для качественного обслуживания клиентов, управления рисками и оптимизации затрат. Сейчас банк использует Big data для управления рисками, борьбы с мошенничеством, сегментации и оценки кредитоспособности клиентов, управления персоналом, прогнозирования очередей в отделениях, расчёта бонусов для сотрудников и других задач
«ВТБ24» пользуется большими данными для сегментации и управления оттоком клиентов, формирования финансовой отчётности, анализа отзывов в соцсетях и на форумах. Для этого он применяет решения Teradata, SAS Visual Analytics и SAS Marketing Optimizer.
«Альфа-Банк» за большие данные взялся в 2013 году. Банк использует технологии для анализа соцсетей и поведения пользователей сайта, оценки кредитоспособности, прогнозирования оттока клиентов, персонализации контента и вторичных продаж. Для этого он работает с платформами хранения и обработки Oracle Exadata, Oracle Big data Appliance и фреймворком Hadoop.
«Тинькофф-банк» с помощью EMC Greenplum, SAS Visual Analytics и Hadoop управляет рисками, анализирует потребности потенциальных и существующих клиентов. Большие данные задействованы также в скоринге, маркетинге и продажах.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
![Технологии больших данных (big data) (большие данные.) [реферат №304]](https://psiola-center.ru/wp-content/uploads/0/a/9/0a90d59af16b90c78a824364b339a5a8.jpeg)




Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
Поиск болей/инсайтов аудитории
Запомните: покупают не товар, а решение проблемы.
Поэтому чтобы сформировать Big Idea, нужно проделать большую работу по диагностике аудитории и выявлению ее болей: потребительских мотивов и барьеров.
Мотивы – зачем покупателю ваш продукт/услуга? Почему покупает? Как это связано с его жизненными принципами, интересами и целями? Причем цели могут быть как благими и высокими, так и вполне приземленными и даже корыстными.
Барьеры – почему покупатель до сих пор не обратился к вам? Что его останавливает добавить товар в корзину? Например:«Боюсь, что меня осудят»,«Думаю, что сам не справлюсь/это слишком сложно или страшно для меня»,«Я не могу себе этого позволить», «Боюсь, что меня обманут», «Боюсь, быть белой вороной», «Мне это навредит», «Меня не удивить».
Вот три метода выявления болей клиента:
1. Проводим интервью
Первое и главное правило: отвечать за клиентов нельзя
Это вам кажется, что для клиента прежде всего важна низкая цена на товар или бесплатная доставка, а на самом деле все может быть гораздо глубже, например: «покупаю велосипед, потому что он безопасный/скоростной/стильный, и неважно, сколько он стоит»
Второе правило: помните, нам нужна именно целевая аудитория. Не зря же мы ее сегментировали. Поэтому и вопросы анкеты нужно подбирать под определенный сегмент. Тогда не только найдете истину, но и зря не потратите время и бюджет.
Важно не превратить интервьюирование в тест, поэтому не проводите его письменно, крайний вариант – записывайте ответы на диктофон. Общаемся и выясняем мнение людей: что думают, чего хотят, какие есть претензии/идеи/предложения
Используйте именно открытые вопросы, чтобы заставить собеседника говорить.
Плохо: вы покупаете продукцию нашей компании? (ответ: да/нет)
Хорошо: какие товары нашего бренда вам нравятся больше и почему? (развернутый ответ)
2. Наблюдаем за потребителем
Если есть такая возможность, понаблюдайте за своим потребителем, проследите, как он взаимодействует с вашим продуктом. Используйте соцсети
Обращайте внимание на детали: настроение, круг общения и интересов, места посещения, профили, на которые подписан, что репостит и какие посты выкладывает сам
Также есть практика наблюдения за клиентами в реальных условиях. Ей пользуются крупные бренды.
Например, компания Procter & Gamble проводит постоянные встречи с клиентами. Они организуют реальные фокус-группы в привычных для участников условиях. Сотрудник компании может провести с участником целый день в качестве стороннего наблюдателя, фиксируя, как тот использует продукт компании. Это помогает понять аудиторию, которая выбирает их бренд.
3. Исследуем конкурентов
Нужно собрать упоминания о конкурентах в сети, причем как отрицательные, так и положительные – любые. Даже из нейтрального отзыва или комментария можно узнать много полезного, а полученные данные использовать не только для поиска инсайтов аудитории, но и при разработке нового позиционирования продукта.
На помощь придут обсуждения в соцсетях, отзовики, форумы, обзоры на YouTube, специальные сервисы по поиску упоминаний брендов (Youscan.ru, IQ Buzz, Brand Analytics, Wobot, Babkee), а также хорошей альтернативой может стать использование Яндекс.Блогов. Ну или просто гуглим.





